Podcasts and Mobile
I've started to build out an MVP of the mobile app and I've been working on podcasts.
<03.07.25>
Mobile App Development
I’ve come to the conclusion that if I want to make any money from Langchats, it has to be mobile first, and I want to give users the best mobile experience possible. I’m going to build the admin system in Next.js as well as the marketing site, but ultimately the app has to be mobile first.
I still want to prove that I can build production-ready, B2B-level SaaS applications using Next.js, because ultimately, if (or when) I have to get a job again, I want to show companies that I can build with their stack. So it’s of the utmost importance to me that I can demonstrate this.
Today I’ve started building the mobile app for Langchats. Extremely early days. I’ve essentially just been setting up the project template and general file structure using Expo (React Native framework).
The last time I tried to build Langchats on mobile, it was a horrible experience. I’m praying that LLM-aided development makes this a far smoother process this time around.
Podcast Feature
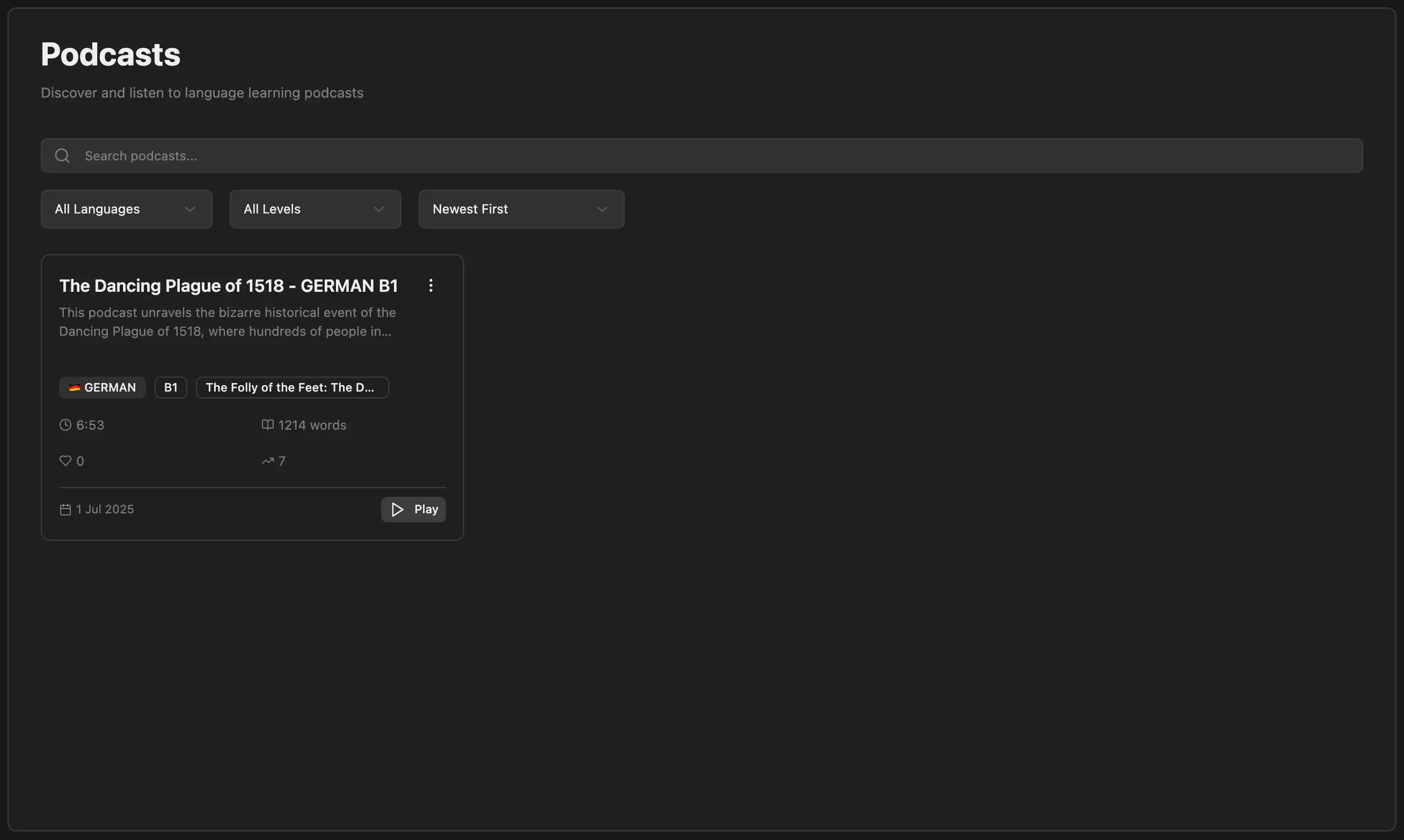
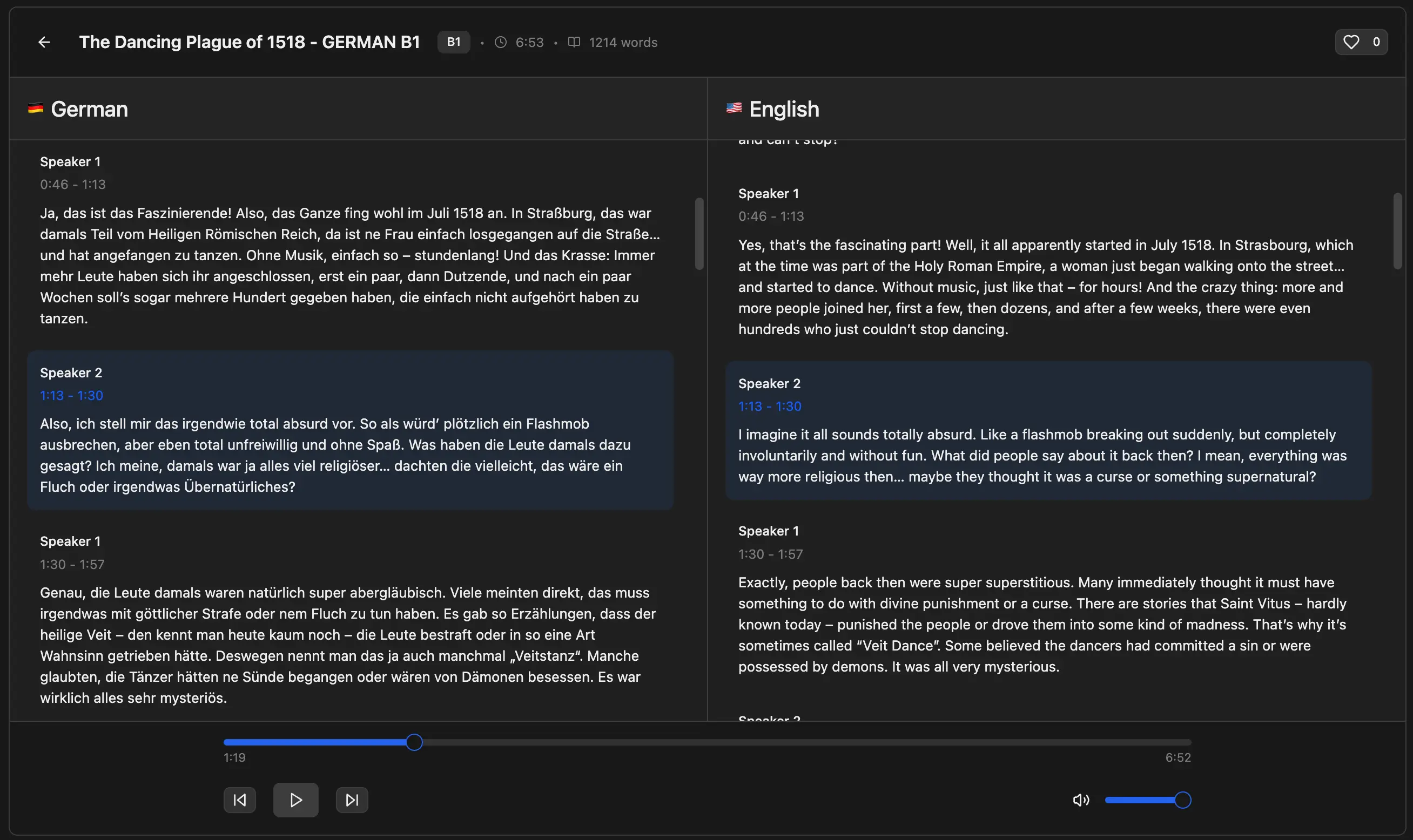
I’ve almost finished building out a new podcast feature in Langchats. This will give users pre-made, short, 5 to 10 minute podcast-style audio recordings with dual-reader transcripts.
I’m using the latest Gemini 2.5 Pro Preview TTS and it is phenomenal. It’s the same TTS technology behind their hit NotebookLM product, and it sounds exceptional. In German, it’s honestly hard for me to tell that it’s not just two native speakers having a conversation together.
The flow kind of works like this:
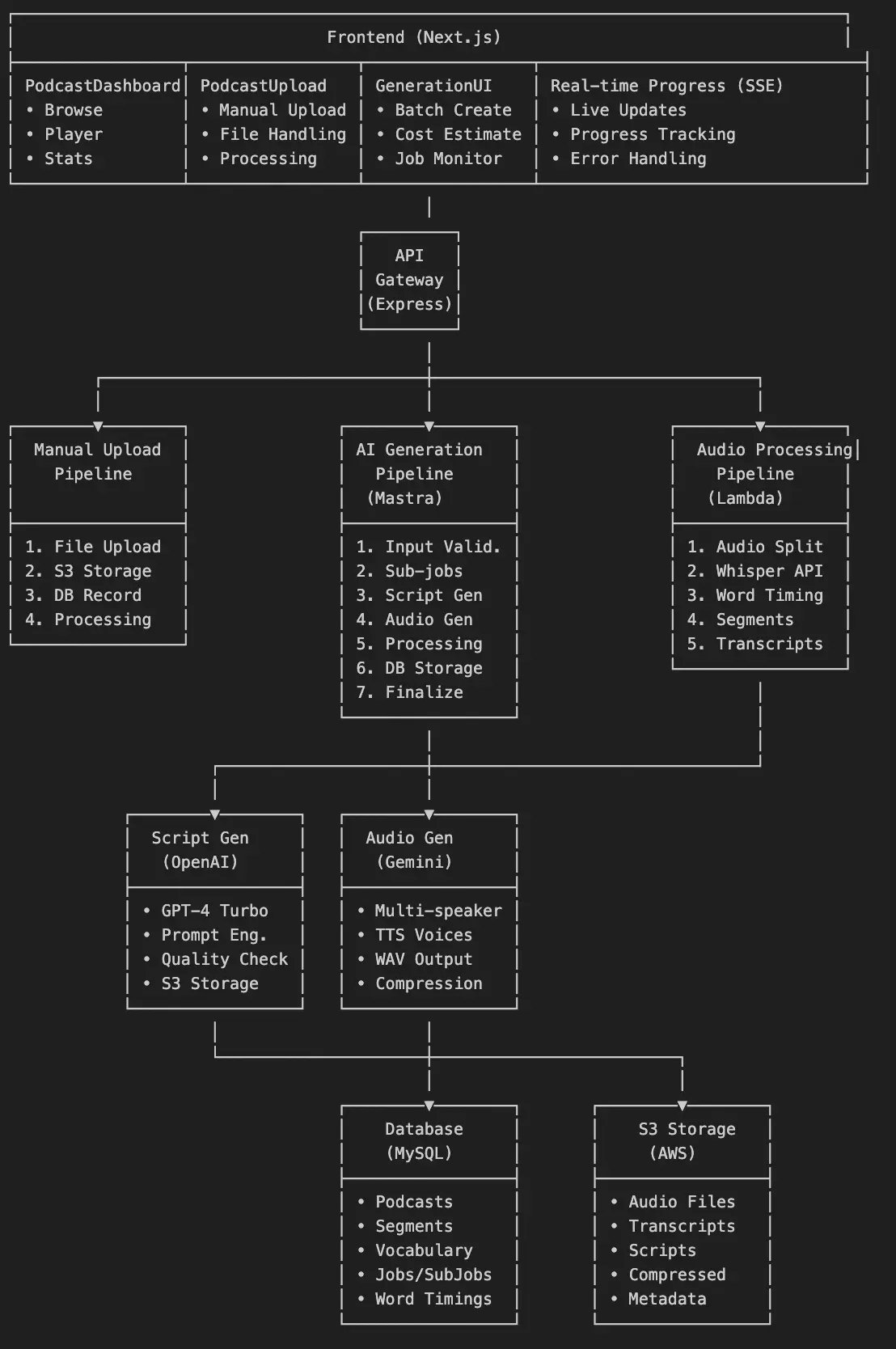
Or in writing, the podcast generation flow looks like this (AI summary):
-
Admin Input
Admin creates a generation job specifying topic, languages, levels, and style. This creates a matrix of sub-jobs (e.g. 3 languages × 3 levels = 9 podcasts). -
Mastra Workflow
Orchestrates a 7-step pipeline with parallel processing, automatic retries, and state persistence. -
Script Generation
OpenAI GPT-4.1 generates conversational scripts in parallel (3 at a time) with speaker tags and language-appropriate content. -
Audio Generation
Google Gemini 2.5 Pro TTS creates multi-speaker audio (2 at a time) using voice profiles (Puck/Kore) with WAV output. -
Audio Processing
AWS Lambda splits audio into chunks, processes them via Whisper API, and returns word-level timestamps and transcript segments. -
Transcript Alignment
Aligns generated scripts with audio timings using speaker segmentation to create perfect synchronisation. -
Database Storage
Creates podcast records with transcript segments, word timings, vocabulary extraction, and cost tracking. -
Real-time Updates
Server-Sent Events (SSE) stream live progress updates to the frontend showing completion status and current sub-job. -
Quality Control
Generated podcasts enter a "pending review" status, requiring admin approval before publishing to learners.
This is currently all happening on the main server, but really, all of these Mastra workflows should exist in their own server, or at the very least as proper background jobs.